Verilerin temsillerinden öğrenmek
Makine öğrenmesi yöntemlerinin temelinde yatan fikir, elimizdeki verileri kullanarak girdiler ile çıktılar arasında bir korelasyon kurmak. Böylece bunu matematiksel bir ifadeye yani bir model’e dönüştürebiliyoruz. Fakat bunu algoritmik yada istatistiksel yöntemler kullanarak yapmak her zaman mümkün olmuyor; istediğimiz hassasiyete sahip modeller oluşturamıyoruz. Bu noktada Derin öğrenme devreye giriyor ve girdileri doğrudan istatistiksel yöntemler ile çıktıya adreslemek yerine ara katmanlar oluşturarak, verileri kademe kademe dönüştürerek girdiler ile çıktılar arasındaki kalıpları oluşturuyoruz. Bunun için sınir ağları (neural networks) denilen mekanizmaları kullanıyoruz.
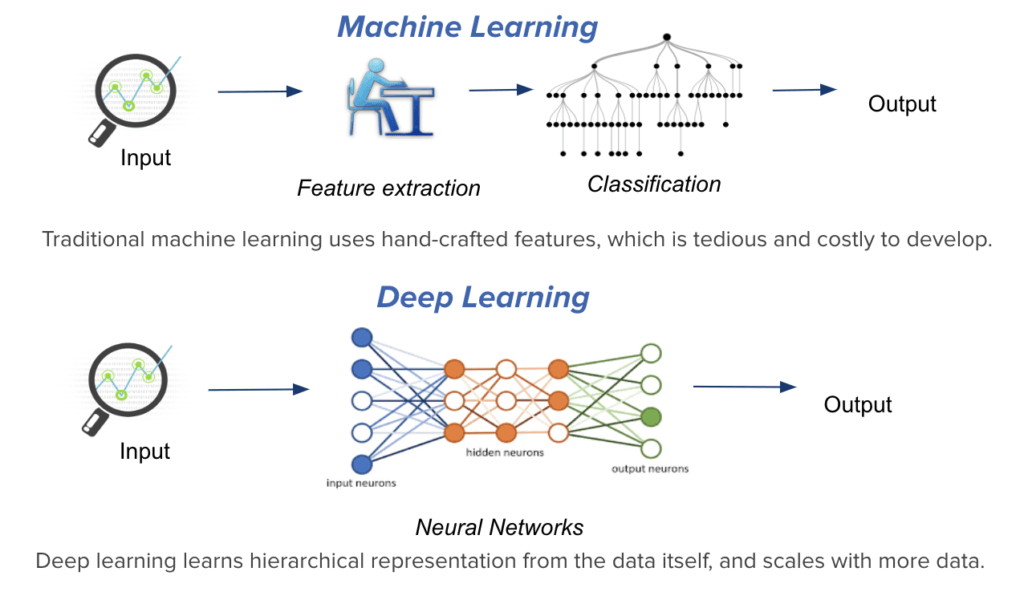
Derin öğrenme konusuna geçmeden önce verilerin temsillerini (representation) oluşturmak konusuna bakmakta fayda var. “Deep Learning with python” kitabında François Chollet bu konuyu mükemmel anlatmış:
Makine öğrenimi yapmak için üç şeye ihtiyacımız var:
- Giriş veri noktaları — Örneğin, görev konuşma tanıma ise, bu veri noktaları konuşan insanların ses dosyaları olabilir. Görev resim etiketleme ise, bunlar resim olabilir.
- Beklenen çıktı örnekleri — Bir konuşma tanıma görevinde bunlar, ses dosyalarının insan tarafından oluşturulmuş transkriptleri olabilir. Bir görüntü görevinde, beklenen çıktılar “köpek”, “kedi” vb. Etiketler olabilir.
- Algoritmanın iyi bir iş yapıp yapmadığını ölçmenin bir yolu — Bu, algoritmanın mevcut çıktısı ile beklenen çıktı arasındaki mesafeyi belirlemek için gereklidir. Ölçüm, algoritmanın çalışma şeklini ayarlamak için bir geri bildirim sinyali olarak kullanılır. Bu ayarlama adımı (optimizasyon), öğrenme dediğimiz şeydir.
Bir makine öğrenimi modeli, girdi verilerini anlamlı çıktılara dönüştürmek için kullanılır. Bu nedenle, makine öğrenimi ve derin öğrenmedeki temel sorun, verileri anlamlı bir şekilde dönüştürmektir: başka bir deyişle, eldeki girdi verilerinin yararlı temsillerini - bizi beklenen çıktıya yaklaştıran temsilleri - öğrenmek.
Peki temsil nedir? Özünde, verilere bakmanın farklı bir yoludur: verileri temsil etmek veya kodlamak. Örneğin, renkli bir görüntü RGB formatında (kırmızı-yeşil-mavi) veya HSV formatında (ton-doygunluk-değeri) kodlanabilir: bunlar aynı verinin iki farklı temsilidir. Bir temsilde zor olabilecek bazı görevler, diğeriyle kolay hale gelebilir. Örneğin, “görüntüdeki tüm kırmızı pikselleri seçme” görevi RGB formatında daha basitken, “görüntüyü daha az doygun hale getir” görevi HSV ile daha basittir.
Makine öğrenimi modellerinin tümü, girdi verileri için uygun temsilleri bulmakla ilgilidir. Buna bir örnek ile bakalım:
Aşağıdaki resimde görüldüğü gibi, birkaç beyaz noktamız ve birkaç siyah noktamız var. Diyelim ki, bir noktanın koordinatlarını (x, y) alabilen ve bu noktanın siyah veya beyaz olma durumunu tahmin edebilen bir algoritma geliştirmek istediğimizi varsayalım. Bu durumda,
- Giriş verisi, noktalarımızın koordinatlarıdır.
- Beklenen çıktılar, noktalarımızın renkleridir.
- Algoritmamızın iyi bir iş yapıp yapmadığını ölçmenin bir yolu, doğru şekilde sınıflandırılan noktaların yüzdesi olabilir.
Burada ihtiyacımız olan şey, beyaz noktaları siyah noktalardan temiz bir şekilde ayıran verilerimizin yeni bir temsilidir. Diğer birçok olasılığın yanı sıra kullanabileceğimiz bir dönüşüm, alttaki şeklin sağ tarafında olduğu gibi bir koordinat değişikliği olabilir.
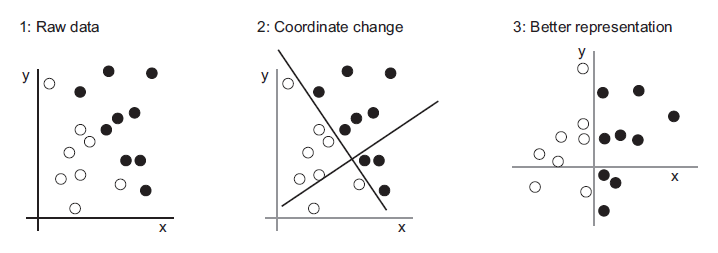
Bu yeni koordinat sisteminde, noktalarımızın koordinatlarının verilerimizin yeni bir temsili olduğu söylenebilir. Bu gösterimle, siyah / beyaz sınıflandırma sorunu basit bir kural olarak ifade edilebilir: “Siyah noktalar öyle ki: x > 0” veya “Beyaz noktalar: x <0” olacak şekildedir. Bu yeni temsil, temelde sınıflandırma problemini çözer. Bu durumda koordinat değişikliğini elle tanımladık. Ancak bunun yerine, sistematik olarak farklı olası koordinat değişikliklerini aramayı deneseydik ve doğru şekilde sınıflandırılan noktaların yüzdesini geri bildirim olarak kullanırsak, o zaman makine öğrenimi yapıyor olurduk. Makine öğrenimi bağlamında öğrenme, daha iyi temsiller için otomatik bir arama sürecini tanımlar.
Tüm makine öğrenimi algoritmaları, verileri belirli bir görev için daha yararlı temsillere dönüştüren bu tür dönüşümleri otomatik olarak bulmaktan oluşur. Makine öğrenimi algoritmaları bu dönüşümleri bulmada genellikle yaratıcı değildir; onlar yalnızca hipotez alanı adı verilen önceden tanımlanmış bir dizi işlemde arama yapıyorlar. Teknik olarak makine öğrenimi budur: önceden tanımlanmış bir olasılık alanı içinde bazı girdi verilerinin faydalı temsillerini bir geri bildirim sinyalinden rehberlik kullanarak aramak. Bu basit fikir, oldukça geniş bir yelpazeyi çözmeye olanak tanır.
Derin öğrenme, makine öğreniminin belirli bir alt alanıdır: giderek anlamlı hale gelen temsillerin birbirini izleyen katmanlarından oluşur. Derin öğrenmedeki derinlik, yaklaşımla elde edilen daha derin herhangi bir anlayışa referans değildir; daha ziyade, bu ardışık temsil katmanları fikrini temsil eder. Bir veri modeline kaç katman katkıda bulunursa, bu modelin derinliği olarak adlandırılır. Modern derin öğrenme genellikle onlarca hatta yüzlerce ardışık temsil katmanını içerir ve bunların tümü, otomatik olarak öğrenir.
Temsil ile öğrenme, bir makinenin ham verilerle beslenmesine ve algılama veya sınıflandırma için gereken temsilleri otomatik olarak keşfetmesine olanak tanıyan bir dizi yöntemdir. Derin öğrenme yöntemleri, her biri bir düzeyde (ham girdiden başlayarak) temsili daha yüksek, biraz daha soyut bir düzeyde bir temsile dönüştüren basit ancak doğrusal olmayan modüller oluşturarak elde edilen, birden çok temsil düzeyine sahip temsil öğrenme yöntemleridir. . Yeterince bu tür dönüşümlerin bileşimi ile çok karmaşık işlevler öğrenilebilir. Sınıflandırma görevleri için, daha yüksek temsil katmanları, girdinin ayrımcılık için önemli olan yönlerini güçlendirir ve ilgisiz varyasyonları bastırır. Örneğin bir görüntü, bir piksel değerleri dizisi biçiminde gelir ve birinci temsil katmanındaki öğrenilen özellikler, tipik olarak görüntüdeki belirli yönlerde ve konumlarda kenarların varlığını veya yokluğunu temsil eder. İkinci katman tipik olarak, kenar konumlarındaki küçük varyasyonlardan bağımsız olarak, belirli kenar düzenlemelerini tespit ederek motifleri tespit eder. Üçüncü katman, motifleri, tanıdık nesnelerin parçalarına karşılık gelen daha büyük kombinasyonlar halinde birleştirebilir ve sonraki katmanlar, nesneleri bu parçaların kombinasyonları olarak algılayacaktır. Derin öğrenmenin temel yönü, bu özellik katmanlarının insan mühendisler tarafından tasarlanmamasıdır: genel amaçlı bir öğrenme prosedürü kullanılarak verilerden öğrenilirler.
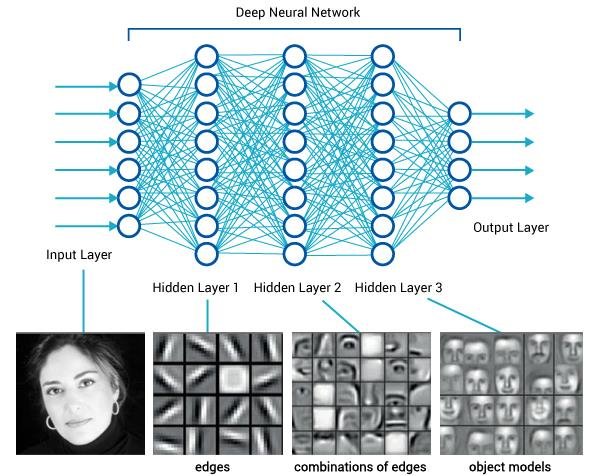
Derin öğrenmede, bu katmanlı temsiller birbirinin üzerine yığılmış gerçek katmanlarda yapılandırılmış sinir ağları adı verilen modelleri oluşturur. Sinir ağı terimi, nörobiyolojiye bir göndermedir, ancak derin öğrenmedeki bazı temel kavramlar kısmen beyin anlayışımızdan ilham alınarak geliştirilmiş olsa da, derin öğrenme modelleri beynin modelleri değildir. Beynin, modern derin öğrenme modellerinde kullanılan öğrenme mekanizmalarına benzer herhangi bir şeyi uyguladığına dair hiçbir kanıt yoktur. Derin öğrenmenin beyin gibi çalıştığını veya beyinden sonra modellendiğini iddia eden popüler bilim makalelerine rastlayabilirsiniz, ancak durum bu değil. Alana yeni başlayanlar için derin öğrenmenin herhangi bir şekilde nörobiyoloji ile ilgili olduğunu düşünmek kafa karıştırıcı ve ters etki yaratabilir; “tıpkı zihnimiz gibi” mistik ve gizem örtüsüne ihtiyacımız yok ve derin öğrenme ile biyoloji arasındaki varsayımsal bağlantılar hakkında okuduğumuz her şeyi sorgulamalıyız. Amaçlarımız doğrultusunda, derin öğrenme, verilerden temsilleri öğrenmek için matematiksel bir çerçevedir.
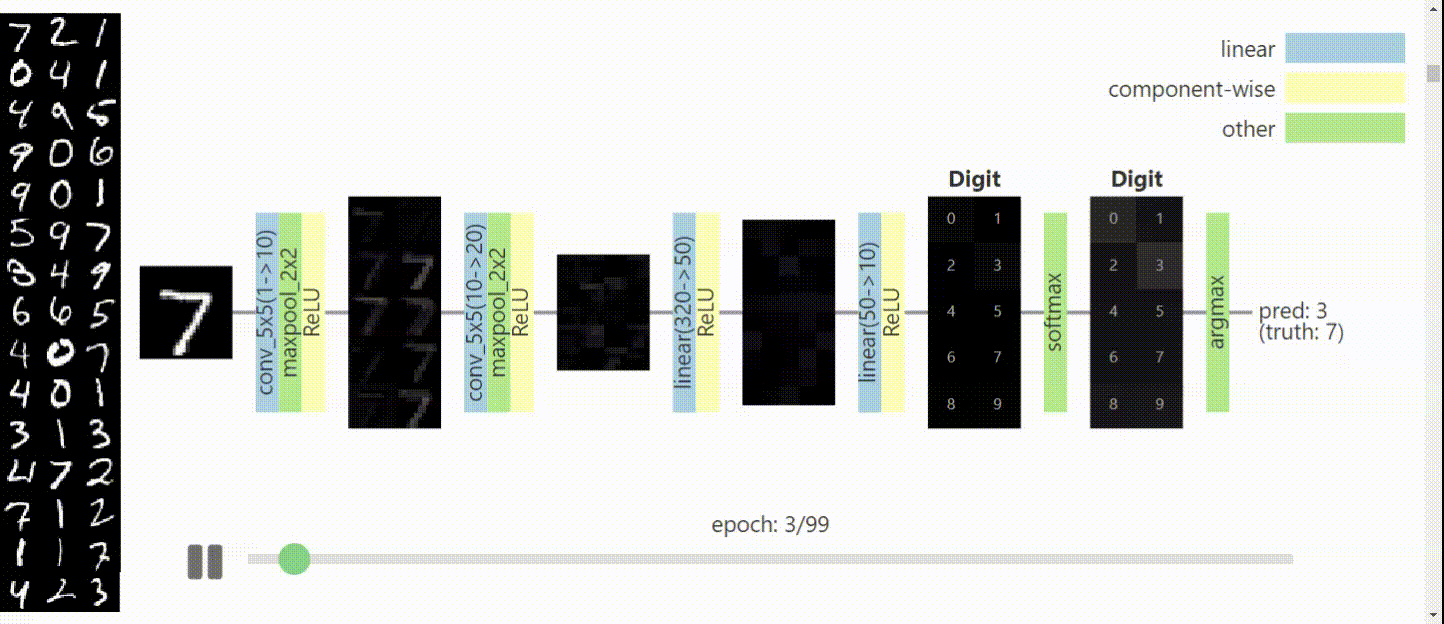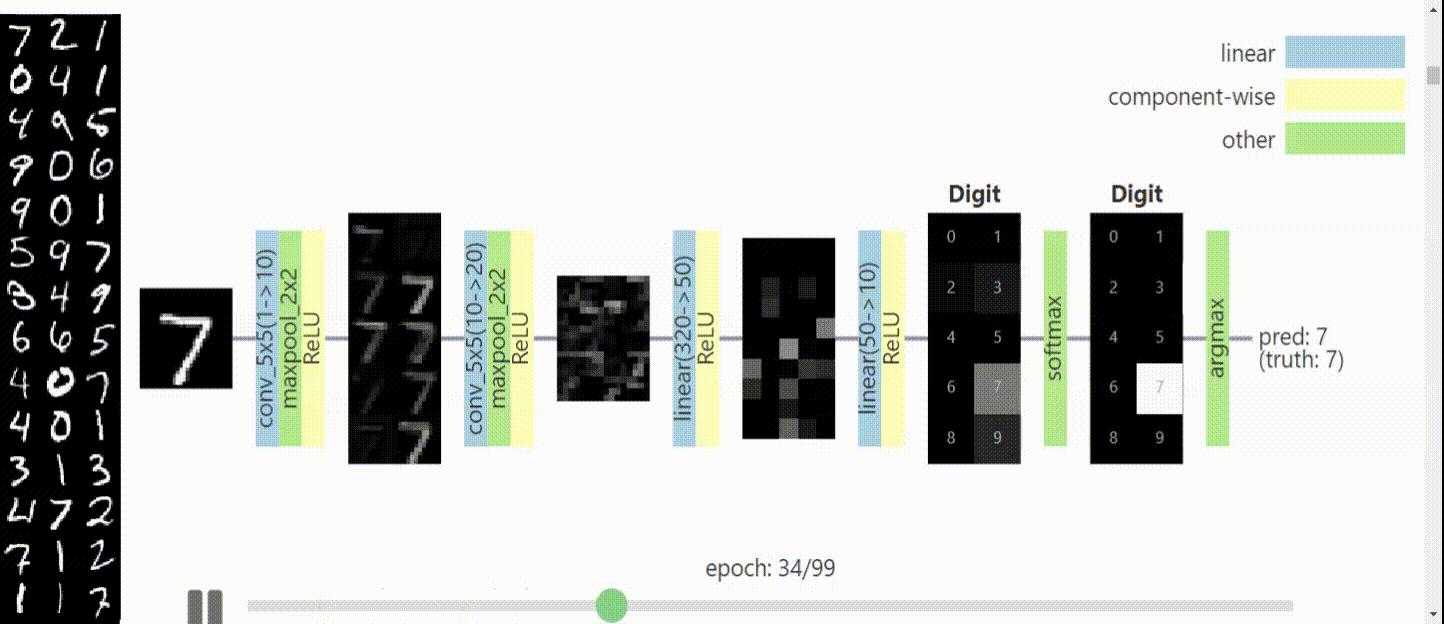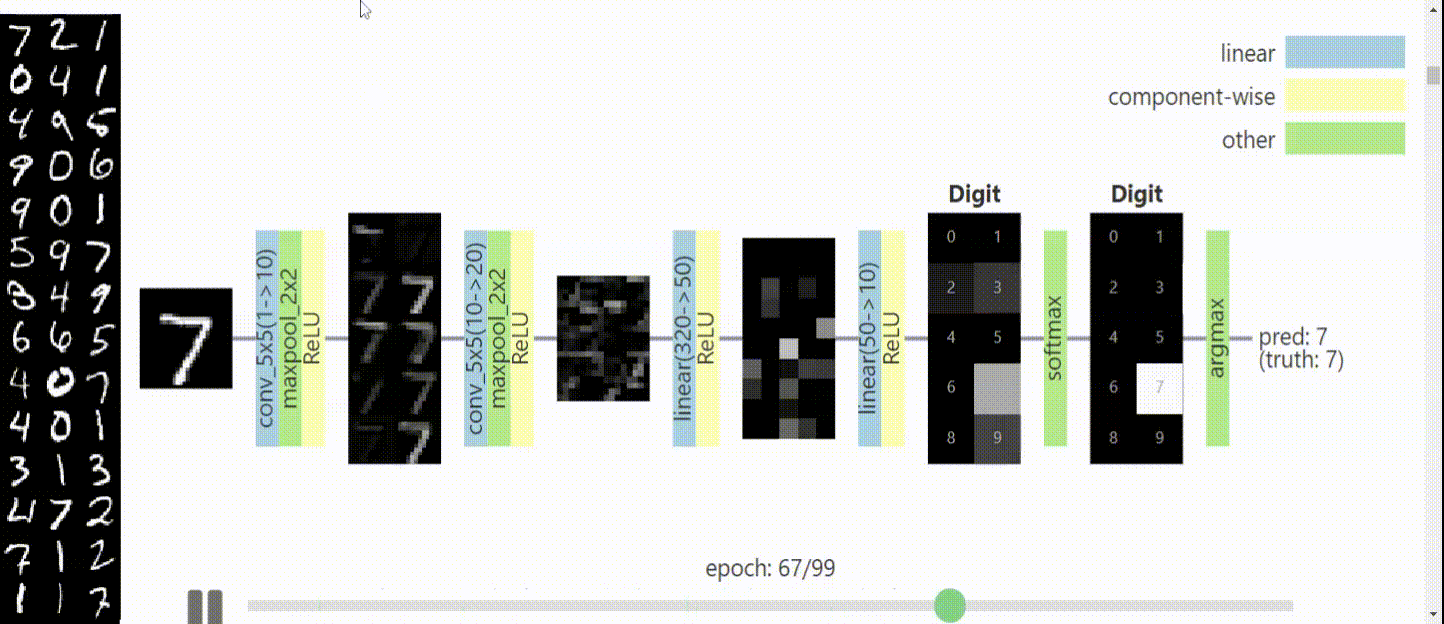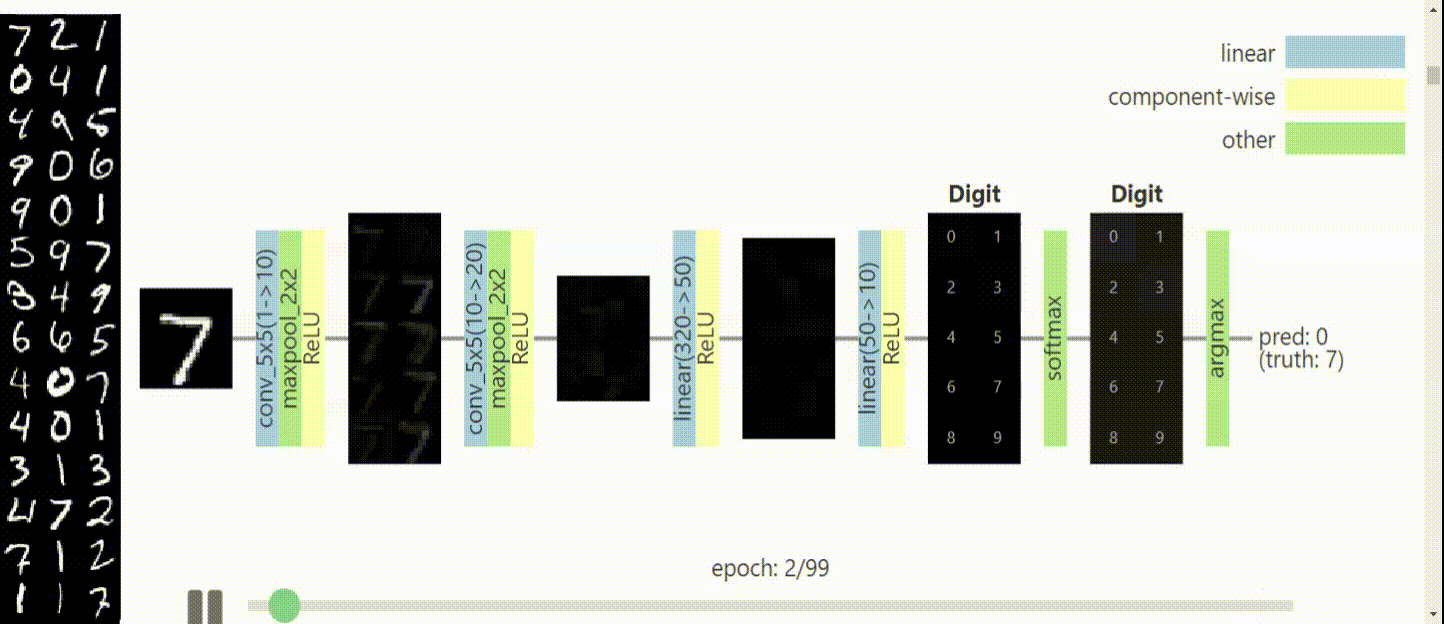
Karmaşık konuları görselleştirek açıklamak konusunda belki de en başarılı Youtube kanalı 3Blue1Brown, sinir ağları ve derin öğrenme konusunda da harika bir iş çıkarmış:
Kaynakça: