Derin Öğrenme Nasıl Çalışır?
Son 10 yıldır Yapay Zeka alanını domine eden Derin Öğrenme konusuna girişi, bu konunun öncüleri olan Yann LeCun, Yoshua Bengio ve Geoffrey Hinton’ın Nature dergisine 2015 yılında yazdıkları bir makalenin giriş paragrafında yaptıkları tanıma göz atarak başlayalım:
” Derin öğrenme, birden çok işleme katmanından oluşan hesaplama modellerinin, birden çok soyutlama düzeyiyle verilerin temsillerini öğrenmesine olanak tanır… Derin öğrenme, bir makinenin önceki katmandaki temsilden her katmandaki gösterimi hesaplamak için kullanılan dahili parametrelerini nasıl değiştirmesi gerektiğini belirtmek için geri yayılım algoritmasını kullanarak büyük veri kümelerindeki karmaşık yapıyı keşfeder…”
Derin öğrenme, uzun yıllardır yapay zeka topluluğunun en iyi girişimlerine direnen sorunları çözmede büyük ilerlemeler sağlıyor. Yüksek boyutlu verilerdeki karmaşık yapıları keşfetmede çok iyi olduğu ortaya çıktı ve bu nedenle bilim, iş dünyası ve kamusal birçok alana uygulanabiliyor. Derin öğrenmenin yakın gelecekte çok daha fazla başarıya sahip olacağı düşünülüyor; çünkü elle çok az mühendislik gerektiriyor. Böylece mevcut hesaplama ve veri miktarındaki artışlardan kolayca yararlanabiliyor. Derin sinir ağları için şu anda geliştirilmekte olan yeni öğrenme algoritmaları ve mimarileri yalnızca bu ilerlemeyi hızlandıracaktır.
Derin olsun ya da olmasın makine öğreniminin en yaygın biçimi denetimli öğrenmedir. Görüntüleri örneğin bir ev, bir araba, bir kişi veya bir evcil hayvan içerecek şekilde sınıflandırabilen bir sistem inşa etmek istediğimizi hayal edelim. Önce, her biri kendi kategorisiyle etiketlenmiş büyük bir ev, araba, insan ve evcil hayvan görsel veri seti topluyoruz. Eğitim sırasında, makineye bir resim gösterilir ve her kategori için bir puan vektörü şeklinde bir çıktı üretir. Resmin ait olduğu kategorinin tüm kategoriler arasında en yüksek puana sahip olmasını istiyoruz, ancak bunun eğitimden önce gerçekleşmesi pek olası değil. Eğitim esnasında, çıktı puanları ile istenen puan örüntüsü arasındaki hatayı (veya mesafeyi) hesaplıyoruz. Makine daha sonra bu hatayı azaltmak için dahili ayarlanabilir parametrelerini değiştirir. Genellikle ağırlıklar olarak adlandırılan bu ayarlanabilir parametreler, makinenin giriş-çıkış fonksiyonunu tanımlayan “katsayılar” olarak görülebilen gerçek sayılardır. Tipik bir derin öğrenme sisteminde, makineyi eğitmek, yani bu ayarlanabilir ağırlıkların en doğru değerlerini bulabilmek için yüz milyonlarca etiketli örnek gerekebilir. Ağırlık vektörünü doğru bir şekilde ayarlamak için, öğrenme algoritması, her ağırlık için, ağırlık küçük bir miktar artırılırsa hatanın ne kadar artacağını veya azalacağını gösteren bir gradyan vektörü (gradient descent - gradyan inişi yada dereceli azalma) hesaplar. Ağırlık vektörü daha sonra gradyan vektörünün tersi yönde ayarlanır.
“Gradient Descent, bir fonksiyonun minimumunu bulmak için birinci mertebeden yinelemeli bir optimizasyon algoritmasıdır. Hem makine öğrenmesi hem de derin öğrenme de ağırlık dediğimiz öğrenme modelinin katsayılarının en optimum değerlerini bulmak için yaygın olarak kullanılır. Burada amaç: modeli eğitirken başlangıçta rastgele değerler atadığımız ağırlıkların eğitim esnasında adım adım iyileştirilerek optimum değerlerin bulunmasıdır. Modelin hesapladığı çıktı değerleri ile eğitim setinde yer alan etiket değerleri arasındaki farkı modelleyen hata fonksiyonunun minimum değerine gitmeyi sağlayacak şekilde oluşturulan modelin ağırlıklarının ayarlanmasıdır.”
Biyolojik nöronlardan yola çıkarak adım adım sinir ağlarını ve derin öğrenmenin nasıl çalıştığını inceleyelim…
Biyolojik nöron’dan yapay nöron’lara
İnsanoğlu tarih boyunca yaptığı sayısız icat için doğadan ilham almıştır. Yapay sinir ağları konusunda da benzer bir durum sözkonusu. Her ne kadar doğal beyin faliyetleri ilham alınarak başlamış olsa da, gelinen noktada yapay sinir ağları teknolojilerinin çalışma şekli doğal beyin ile aynı olduğu söylenemez.
Fakat sinir sistemi ve beynin çalışması konusunda yapılan çalışmalar ve edinilen bilgilerden ilham alınarak makine öğrenmesi alanında analoji yapılmasının, derin öğrenme konusuna yaptığı katkılar yadsınamaz.
Derin Öğrenme konusunun çekirdeği Yapay Sinir Ağları’dır. Çok yönlü, güçlü ve ölçeklenebilir olmaları, aşağıdaki gibi son derece zor görevleri mümkün hale getirmektedir:
- Milyarlarca görüntüyü sınıflandırma (ör. Google Görseller),
- Konuşma tanıma hizmetlerini (ör. Apple’ın Siri’si) güçlendirme,
- En iyi videoları önerme (örneğin, YouTube)
- Kendisine karşı milyonlarca kez oyun oynayarak Go oyununda dünya şampiyonunu yenmeyi öğrenmek (DeepMind’s Alpha-Zero).
Biyolojik beynin en temel parçası olan nöronlara bir bakalım;
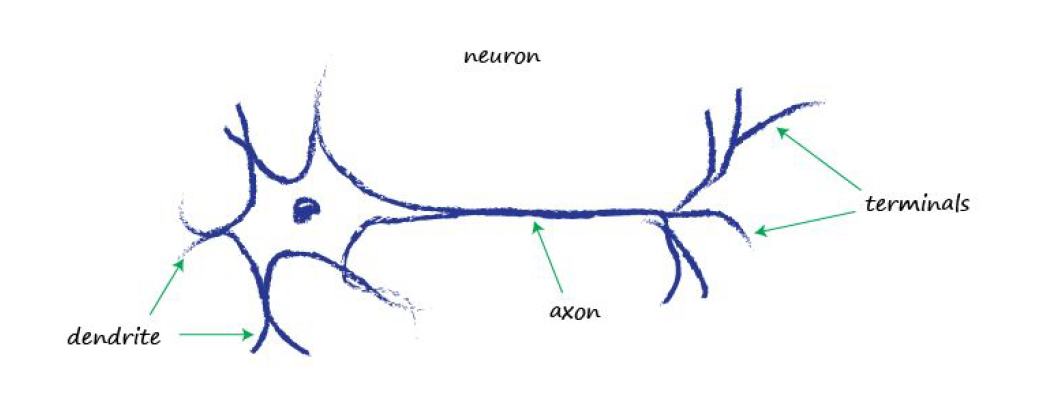
Nöronlar, çeşitli formları olmasına rağmen, hepsi aksonlar boyunca dendritlerden terminallere bir uçtan diğerine bir elektrik sinyali iletirler. Bu sinyaller daha sonra bir nörondan diğerine aktarılır. Vücudunuzun ışığı, sesi, dokunma basıncını, ısıyı vb. Algılaması budur. Özelleştirilmiş duyu nöronlarından gelen sinyaller, sinir sisteminiz boyunca beyninize iletilir ve beynin kendisi de çoğunlukla nöronlardan yapılır.
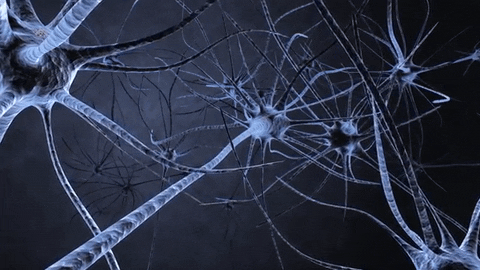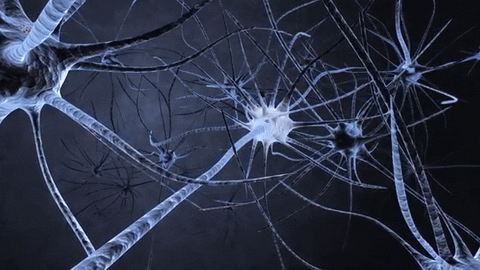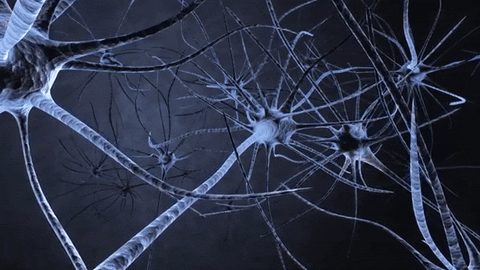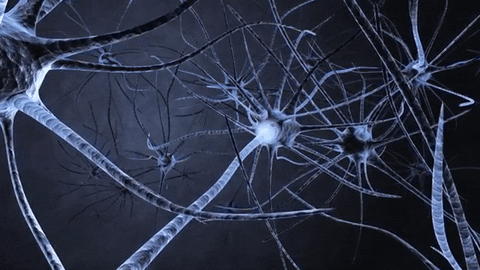
Bireysel biyolojik nöronlar oldukça basit bir şekilde davranıyor gibi görünüyorlar, ancak her biri tipik olarak binlerce başka nörona bağlı olan milyarlarca nörondan oluşan geniş bir ağda organize edilmişlerdir. Oldukça karmaşık hesaplamalar, karmaşık bir karınca yuvasının basit karıncaların birleşik çabalarından ortaya çıkması gibi, oldukça basit nöronlardan oluşan geniş bir ağ tarafından gerçekleştirilebilir. Biyolojik sinir ağlarının mimarisi hala aktif araştırmanın konusudur, ancak beynin bazı kısımları haritalandırılmıştır ve görünen o ki, nöronlar genellikle ardışık katmanlar halinde düzenlenmiştir.
Yapay Sinir Ağları Mimarisi
Bir sinir ağı, farklı katmanlardan oluşur. Her katman birden fazla nöron içerir.
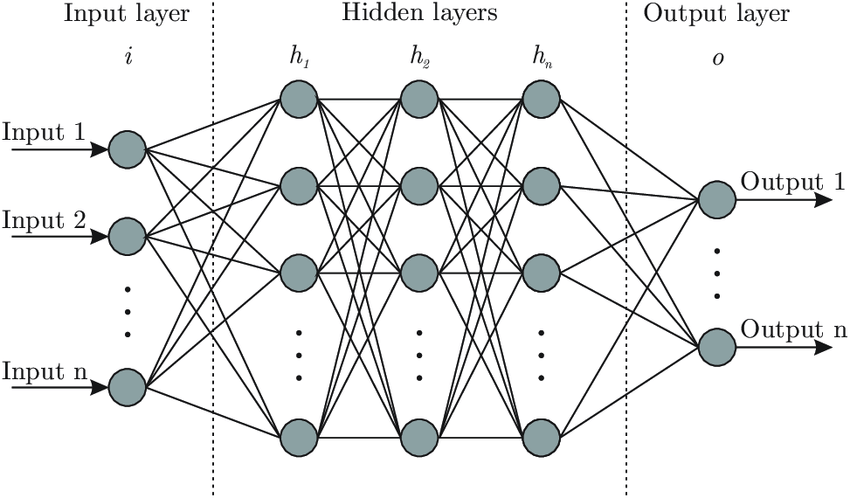
Tipik bir sinir ağı, birkaç yapay nöron katmanından oluşur. Bir sinir ağındaki ilk katmana giriş katmanı denir. Burası sinir ağına girdi beslediğimiz yerdir. Bir sinir ağının son katmanına çıktı katmanı denir. Bu, dönüştürülen verilerin sinir ağından çıktığı yerdir. Bir sinir ağının çıktısı, ağ tarafından yapılan tahmini temsil eder.
Sinir ağının giriş ve çıkış katmanı arasında bir veya daha fazla gizli katman bulabilirsiniz. Girdi ve çıktı arasındaki katmanlar gizlidir çünkü genellikle bu katmanlardan geçen verileri gözlemlemeyiz.
Sinir ağları matematiksel yapılardır. Bir sinir ağından geçen veriler, sayılar olarak kodlanır. Bu, bir sinir ağıyla işlemek istediğiniz her şeyin sayılardan oluşan vektörler olarak kodlanması gerektiği anlamına gelir.
Yapay sinir ağları nasıl çalışıyor?
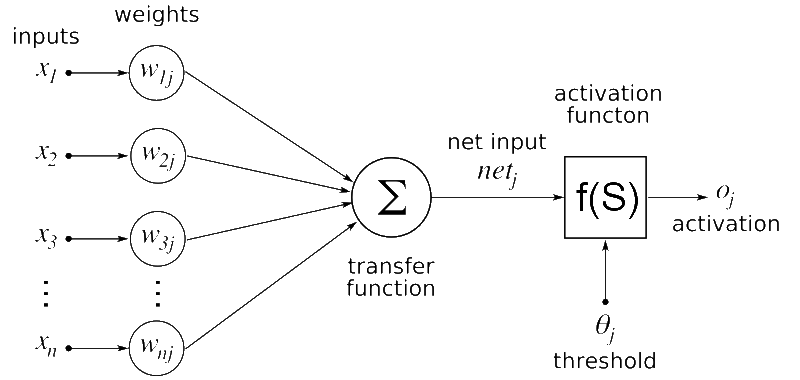
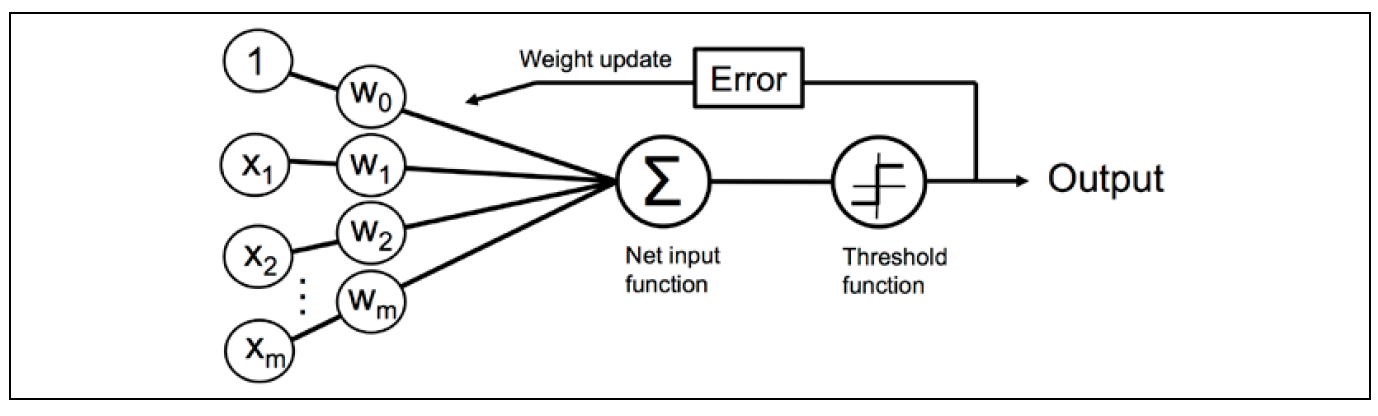
Bir sinir ağının çekirdeği yapay nörondur. Yapay nöron, verilerdeki kalıpları tanımak için eğitebileceğimiz bir sinir ağındaki en küçük birimdir. Sinir ağındaki her yapay nöronun bir veya daha fazla girişi vardır. Vektör girdisinin her biri bir ağırlık (parametre) alır:
https://commons.wikimedia.org/wiki/File:Artificial_neural_network.png
Sinir ağındaki her yapay nöronun bir veya daha fazla girişi vardır. Vektör girdilerinin her biri bir ağırlık alır. Nöronun her girişi için sağlanan sayılar bu ağırlıkla çarpılır. Bu çarpmanın çıktısı daha sonra nöron için toplam bir aktivasyon değeri üretmek için toplanır.
Bu aktivasyon sinyali daha sonra bir aktivasyon fonksiyonundan geçirilir. Aktivasyon işlevi, bu sinyal üzerinde doğrusal olmayan bir dönüşüm gerçekleştirir. Örneğin: giriş sinyalini işlemek için rektifiye edilmiş bir doğrusal fonksiyon kullanır:
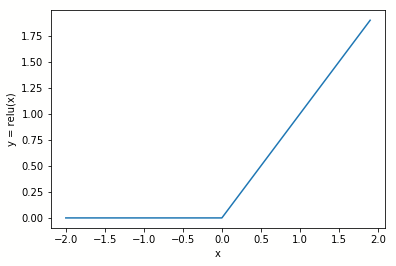
Düzeltilmiş doğrusal fonksiyon, negatif aktivasyon sinyallerini sıfıra dönüştürür, ancak pozitif bir sayı olduğunda o değeri almaktadır.
Bir diğer popüler etkinleştirme işlevi sigmoid işlevidir. Negatif değerleri 0’a ve pozitif değerleri 1’e dönüştürdüğü için rektifiye edilmiş doğrusal fonksiyondan biraz farklı davranır. Bununla birlikte, sinyalin doğrusal bir şekilde dönüştürüldüğü -0.5 ile +0.5 arasındaki aktivasyonda bir eğim vardır.
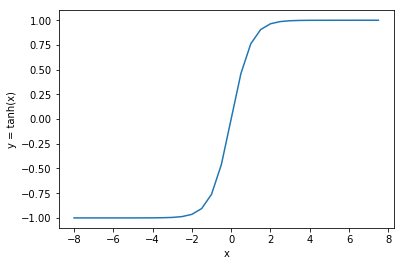
Yapay nöronlardaki aktivasyon fonksiyonları, sinir ağında önemli bir rol oynar. Bu doğrusal olmayan dönüşüm işlevleri nedeniyle, sinir ağının verilerdeki doğrusal olmayan ilişkilerle çalışabilmesi sağlanır.
Sinir ağı ile çıktı tahmin etme Nöron katmanlarını bir araya getirerek, doğrusal olmayan dönüşümlere ve eğitilebilir ağırlıklara sahip bir işlev yaratırız, böylece karmaşık ilişkileri tanımayı öğrenebilir. Bunu görselleştirmek için, sinir ağını önceki bölümlerden matematiksel bir formüle dönüştürelim. İlk olarak, tek bir katmanın formülüne bir göz atalım:
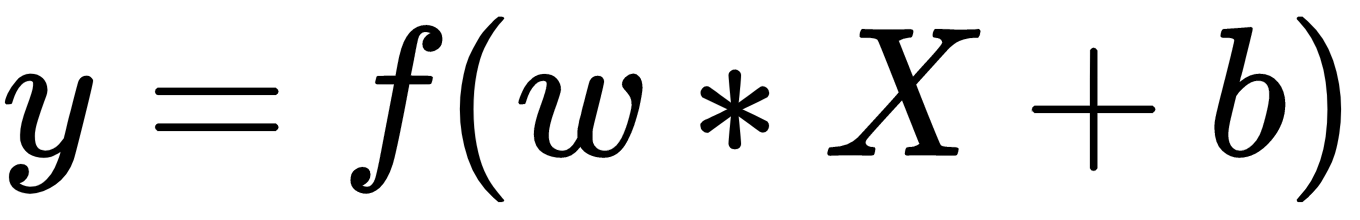
X değişkeni, sinir ağındaki katman için girdiyi temsil eden bir vektördür. W parametresi, girdi vektörü X’teki her bir öğe için bir ağırlık vektörünü temsil eder. Birçok sinir ağı uygulamasında ek bir terim olan b eklenir, buna önyargı (bias) denir ve temel olarak genel girdi düzeyini artırır veya azaltır; nöronu etkinleştirmek için gereklidir. Son olarak, katman için etkinleştirme işlevi olan bir f işlevi vardır.
Artık tek bir katmanın formülünü gördüğünüze göre, sinir ağı formülünü oluşturmak için ek katmanları bir araya getirelim:
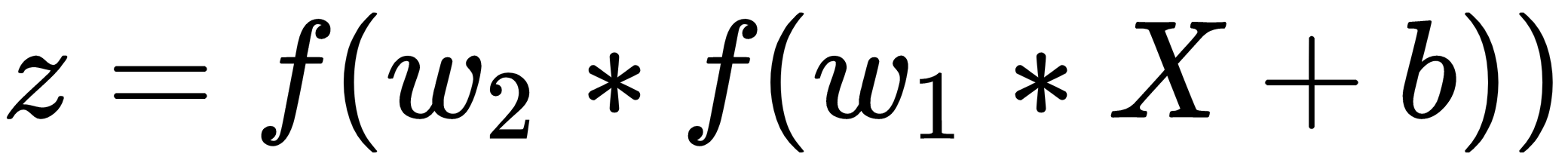
Formülün nasıl değiştiğine dikkat edelim. Şimdi, başka bir katman işlevine sarılmış ilk katmanın formülüne sahibiz. Sinir ağına daha fazla katman eklediğimizde bu işlevlerin sarılması veya istiflenmesi devam eder. Her katman, sinir ağını eğitmek için optimize edilmesi gereken daha fazla parametre sunar. Ayrıca sinir ağının, içine aktardığımız verilerden daha karmaşık ilişkiler öğrenmesine de olanak tanır.
Bir sinir ağı ile bir tahmin yapmak için, sinir ağındaki tüm parametreleri doldurmamız gerekir. Bir sinir ağındaki parametreleri nasıl optimize edeceğimizi henüz konuşmadık. Bir sinir ağındaki her bir bileşenin üzerinden geçelim ve onu eğitirken birlikte nasıl çalıştıklarını keşfedelim:
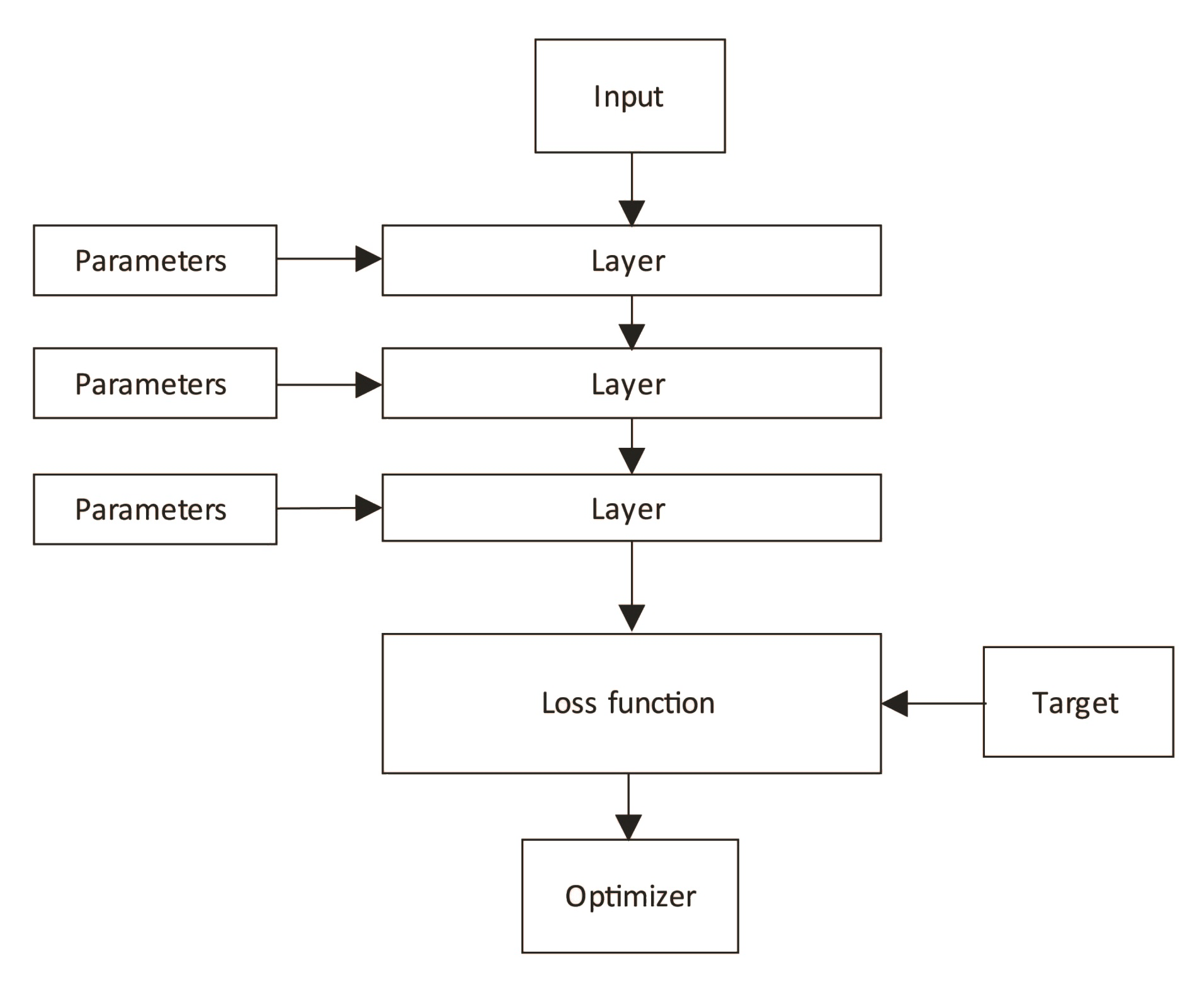
Bir sinir ağının birbirine bağlı birkaç katmanı vardır. Her katmanın optimize etmek istediğimiz bir dizi eğitilebilir parametresi olacaktır. Bir sinir ağını optimize etmek, geri yayılım (Back propogation) adı verilen bir teknik kullanılarak yapılır. Önceki diyagramdaki w1, w2 ve w3 parametrelerinin değerlerini kademeli olarak optimize ederek bir kayıp fonksiyonunun çıktısını en aza indirmeyi hedefliyoruz.
Bir sinir ağı için kayıp işlevi birçok şekilde olabilir. Tipik olarak, beklenen çıktı, Y ve sinir ağı tarafından üretilen gerçek çıktı -şapkalı Y- arasındaki farkı ifade eden bir fonksiyon seçeriz. Örneğin: aşağıdaki kayıp fonksiyonunu kullanabiliriz:
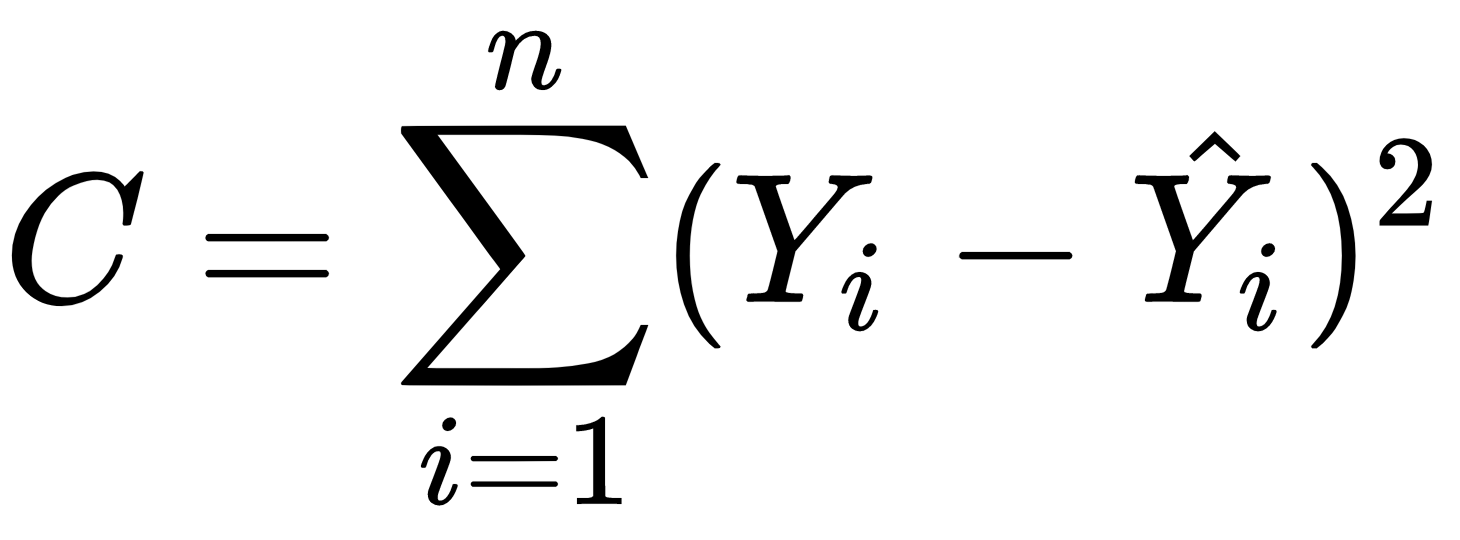
Öncelikle sinir ağı eğitim verileri ile başlatılır. Bunu modeldeki tüm parametreler (ağırlıklar) için rastgele değerlerle yapabiliriz.
Sinir ağını başlattıktan sonra, bir tahmin yapmak için verileri sinir ağına besliyoruz. Daha sonra, modelin olmasını beklediğimiz şeye ne kadar yakın olduğunu ölçmek için tahmini çıktıyla birlikte bir kayıp fonksiyonuna besleriz.
Kayıp işlevinden gelen geri bildirim, bir optimize ediciyi beslemek için kullanılır. Optimize edici, her bir parametrenin nasıl optimize edileceğini bulmak için gradyan inişi adı verilen bir teknik kullanır.
Gradyan inişi, sinir ağı optimizasyonunun önemli bir bileşenidir ve kayıp fonksiyonunun ilginç bir özelliği nedeniyle çalışır. Sinir ağındaki parametreler için farklı değerlere sahip bir girdi kümesi için kayıp işlevinin çıktısını görselleştirdiğinizde, şuna benzer görünen bir grafik elde edersiniz:
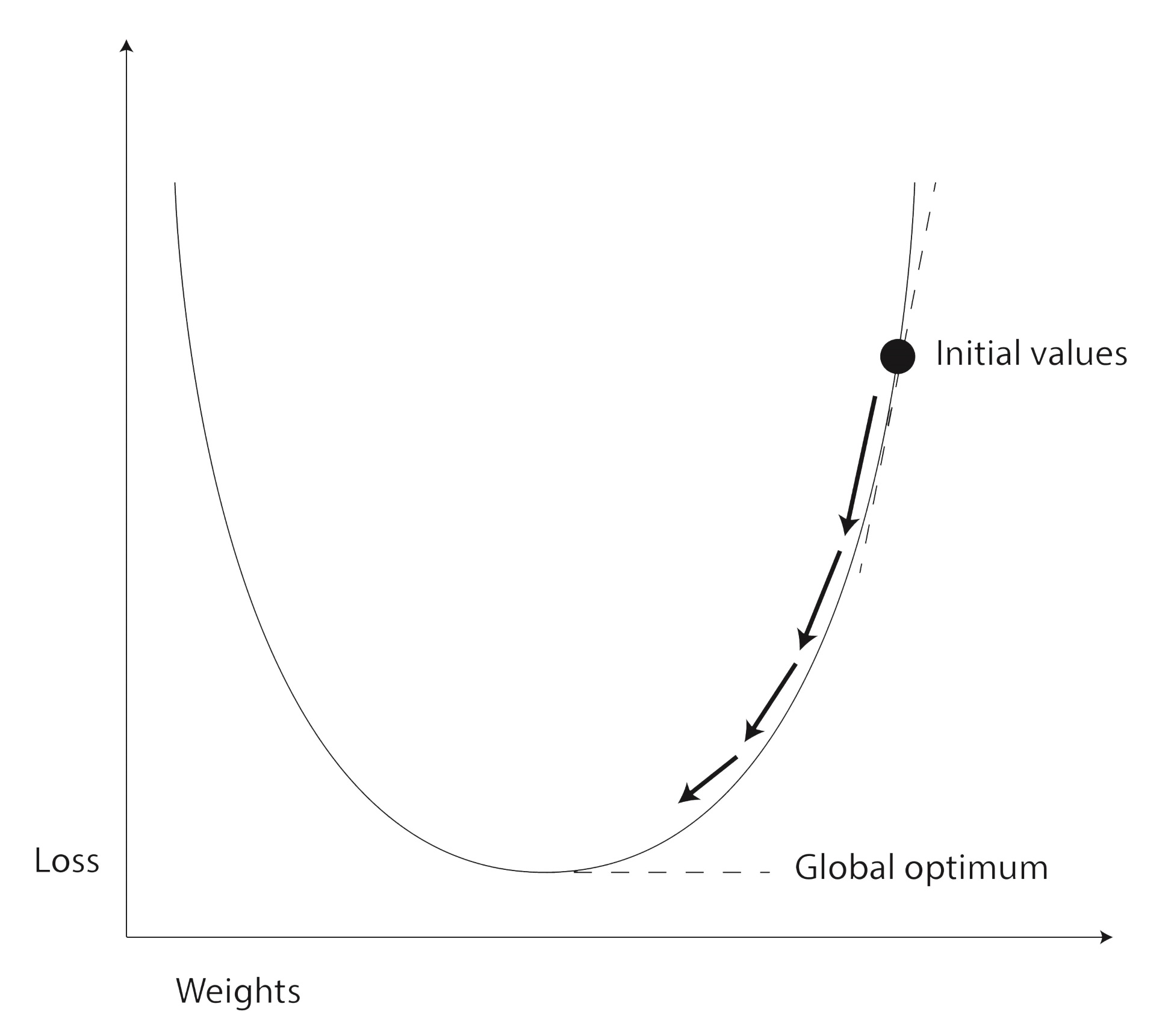
Geri yayılım sürecinin başlangıcında, bu dağ manzarasındaki yamaçlardan birinde bir yerden başlıyoruz. Amacımız, parametrelerin değerlerinin en iyi olduğu noktaya doğru dağdan aşağı yürümek. Bu, kayıp fonksiyonunun çıktısının mümkün olduğunca en aza indirildiği noktadır.
Dağ yamacından iniş yolunu bulabilmemiz için, dağ yamacının mevcut noktasındaki eğimi ifade eden bir fonksiyon bulmamız gerekiyor. Bunu, kayıp işlevinden türetilmiş bir işlev oluşturarak yaparız. Bu türetilmiş fonksiyon bize modeldeki parametrelerin gradyanlarını verir.
Geri yayılım sürecinin bir geçişini gerçekleştirdiğimizde, parametreler için gradyanları kullanarak dağdan bir adım aşağı iniyoruz. Fakat bu inişi kontrollü ve yavaş bir şekilde yapmalıyız. Çünkü çok hızlı hareket edersek, optimum noktayı kaçırabiliriz. Bu nedenle, tüm sinir ağı optimize edicilerinin öğrenme hızı adı verilen bir ayarı vardır. Öğrenme oranı, iniş oranını kontrol eder.
Gradyan-iniş algoritmasında sadece küçük adımlar atarak, sinir ağı parametrelerinin (ağırlıklar) optimum değerlerine ulaşmak için bu işlemi defalarca tekrar etmemiz gerekir.
Kaynakça: